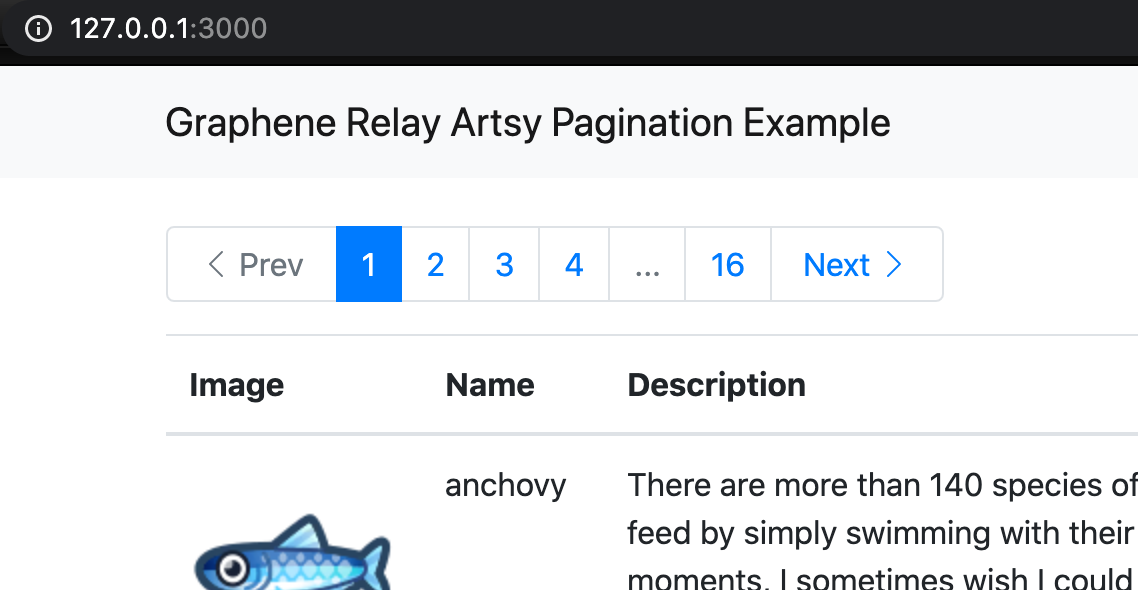
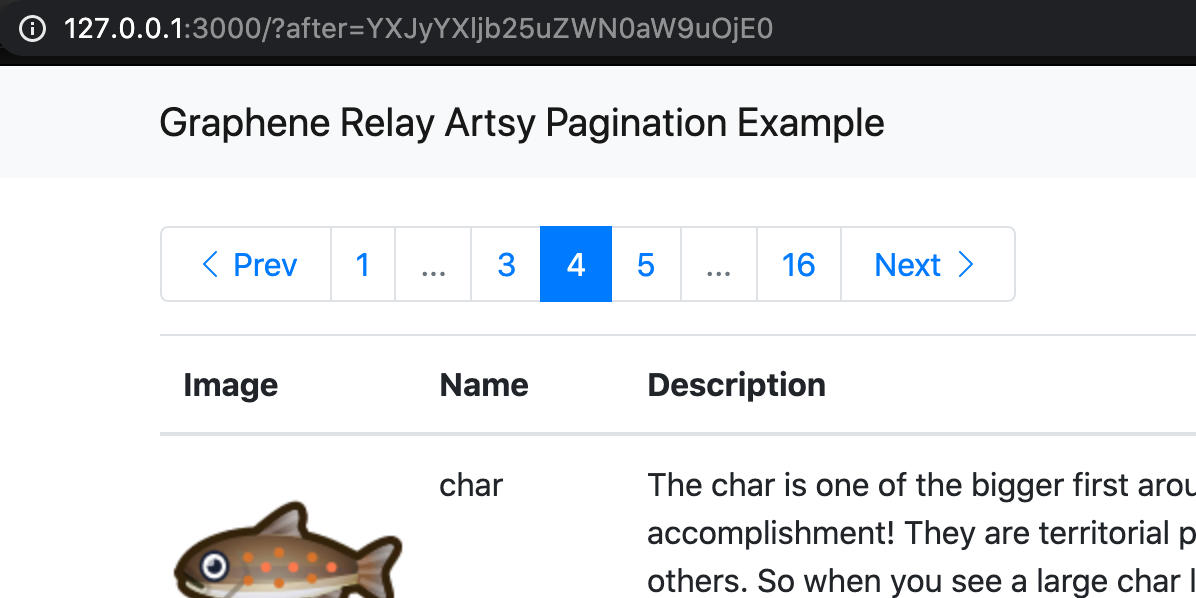
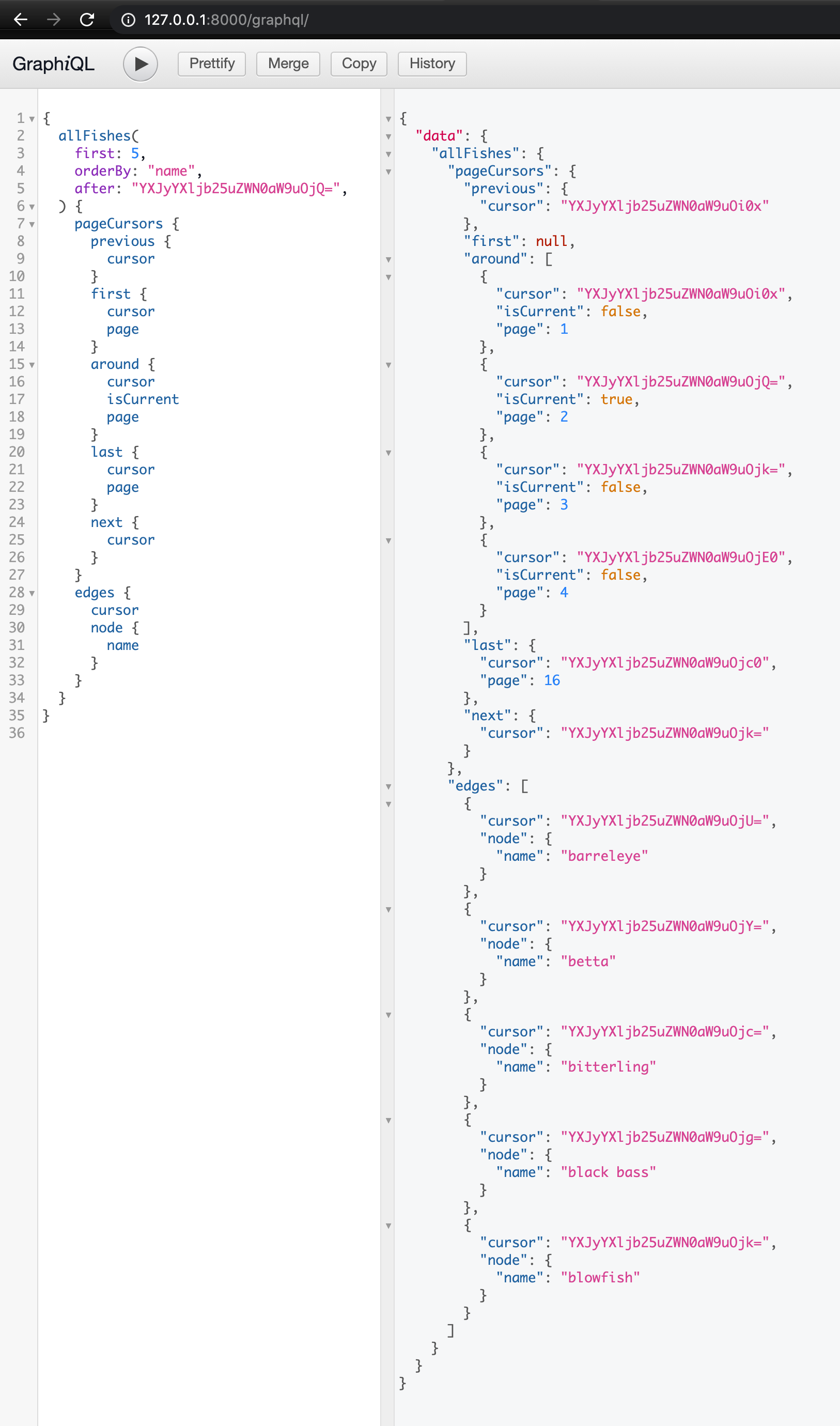
Here are some CSS experiments to test when elements adjust to the height of their container and when they adjust to the height of their content. The script to generate the experiments is on github and the results are shown below. See also my companion page on CSS width.
By default, elements adjust to height of their container when they are
By default, elements adjust to the height of their content when they are
Some elements can be made to adjust to the height of their container by
Some elements can be made to adjust to the height of their content by
Some miscellaneous cases:
- elements in flex column containers with
flex-grow set expand to the height of their content for tall content - for elements in grid containers, setting
height to 100% does NOT limit their height by the height of their container - for elements in grid containers, setting
overflow limits an element's height to the height of its container for tall content - for elements in grid containers, setting
overflow has no effect when align-items is set - for elements in table cell containers, setting
height to 100% does NOT expand an element's height to the height of the table cell container if the height of the table cell container is not explicitly set
See also¶
Block containers¶
Block container - elements in block containers adjust to the height of their content by default
#container-1a
#example-1a
#content-1a
HTML
<div id="container-1a">
<div id="example-1a">
<div id="content-1a" />
</div>
</div>
CSS
#container-1a {
display: block; /* default */
height: 400px;
}
#example-1a {}
#content-1a {
height: 80px;
}
Block container, tall content - elements in block containers adjust to the height of their content even when the content is taller than the container
#container-1b
#example-1b
#content-1b
HTML
<div id="container-1b">
<div id="example-1b">
<div id="content-1b" />
</div>
</div>
CSS
#container-1b {
display: block; /* default */
height: 400px;
}
#example-1b {}
#content-1b {
height: 420px;
}
Block container, height 100% - elements in block containers expand to the height of their container if height is set to 100%
#container-1c
#example-1c
#content-1c
HTML
<div id="container-1c">
<div id="example-1c">
<div id="content-1c" />
</div>
</div>
CSS
#container-1c {
display: block; /* default */
height: 400px;
}
#example-1c {
height: 100%;
}
#content-1c {
height: 80px;
}
Block container, tall content, height 100% - elements in block containers contract to the height of their container if height is set to 100%
#container-1d
#example-1d
#content-1d
HTML
<div id="container-1d">
<div id="example-1d">
<div id="content-1d" />
</div>
</div>
CSS
#container-1d {
display: block; /* default */
height: 400px;
}
#example-1d {
height: 100%;
}
#content-1d {
height: 420px;
}
Flex row containers¶
Flex row container - elements in flex row containers expand to the height of their container by default
#container-3a
#example-3a
#content-3a
HTML
<div id="container-3a">
<div id="example-3a">
<div id="content-3a" />
</div>
</div>
CSS
#container-3a {
align-items: normal; /* default - behaves as stretch in this case */
display: flex;
flex-direction: row; /* default */
height: 400px;
}
#example-3a {}
#content-3a {
height: 80px;
}
Flex row container, tall content - elements in flex row containers contract to the height of their container by default
#container-3b
#example-3b
#content-3b
HTML
<div id="container-3b">
<div id="example-3b">
<div id="content-3b" />
</div>
</div>
CSS
#container-3b {
align-items: normal; /* default - behaves as stretch in this case */
display: flex;
flex-direction: row; /* default */
height: 400px;
}
#example-3b {}
#content-3b {
height: 420px;
}
Flex row container, align-items set - elements in flex row containers adjust to the height of their content if align-items is set to something other than stretch
#container-3c
#example-3c
#content-3c
HTML
<div id="container-3c">
<div id="example-3c">
<div id="content-3c" />
</div>
</div>
CSS
#container-3c {
align-items: flex-start;
display: flex;
flex-direction: row; /* default */
height: 400px;
}
#example-3c {}
#content-3c {
height: 80px;
}
Flex row container, align-items set, tall content - elements in flex row containers adjust to the height of their content if align-items is set to something other than stretch
#container-3d
#example-3d
#content-3d
HTML
<div id="container-3d">
<div id="example-3d">
<div id="content-3d" />
</div>
</div>
CSS
#container-3d {
align-items: flex-start;
display: flex;
flex-direction: row; /* default */
height: 400px;
}
#example-3d {}
#content-3d {
height: 420px;
}
Flex column containers¶
Flex column container - elements in flex columns containers adjust to the height of the content by default
#container-4a
#example-4a
#content-4a
HTML
<div id="container-4a">
<div id="example-4a">
<div id="content-4a" />
</div>
</div>
CSS
#container-4a {
display: flex;
flex-direction: column;
justify-content: normal; /* default */
height: 400px;
}
#example-4a {}
#content-4a {
height: 80px;
}
Flex column container, tall content - elements in flex columns containers adjust to the height of their content even for tall content
#container-4b
#example-4b
#content-4b
HTML
<div id="container-4b">
<div id="example-4b">
<div id="content-4b" />
</div>
</div>
CSS
#container-4b {
display: flex;
flex-direction: column;
justify-content: normal; /* default */
height: 400px;
}
#example-4b {}
#content-4b {
height: 420px;
}
Flex column container, height: 100% - elements in flex column containers expand to the height of their container if height is set to 100%
#container-4c
#example-4c
#content-4c
HTML
<div id="container-4c">
<div id="example-4c">
<div id="content-4c" />
</div>
</div>
CSS
#container-4c {
display: flex;
flex-direction: column;
justify-content: normal; /* default */
height: 400px;
}
#example-4c {
height: 100%;
}
#content-4c {
height: 80px;
}
Flex column container, height: 100%, tall content - elements in flex column containers contract to the height of their container if height is set to 100%
#container-4d
#example-4d
#content-4d
HTML
<div id="container-4d">
<div id="example-4d">
<div id="content-4d" />
</div>
</div>
CSS
#container-4d {
display: flex;
flex-direction: column;
justify-content: normal; /* default */
height: 400px;
}
#example-4d {
height: 100%;
}
#content-4d {
height: 420px;
}
Flex column container, flex-grow - elements in flex column containers expand to the height of their container when flex-grow is set to 1
#container-4e
#example-4e
#content-4e
HTML
<div id="container-4e">
<div id="example-4e">
<div id="content-4e" />
</div>
</div>
CSS
#container-4e {
display: flex;
flex-direction: column;
justify-content: normal; /* default */
height: 400px;
}
#example-4e {
flex-grow: 1;
}
#content-4e {
height: 80px;
}
Flex column container, flex-grow, tall content - elements in flex column containers expand to the height of their content when flex-grow is set to 1
#container-4f
#example-4f
#content-4f
HTML
<div id="container-4f">
<div id="example-4f">
<div id="content-4f" />
</div>
</div>
CSS
#container-4f {
display: flex;
flex-direction: column;
justify-content: normal; /* default */
height: 400px;
}
#example-4f {
flex-grow: 1;
}
#content-4f {
height: 420px;
}
Grid containers¶
Grid container - elements in grid containers expand to the height of the container by default
#container-5a
#example-5a
#content-5a
HTML
<div id="container-5a">
<div id="example-5a">
<div id="content-5a" />
</div>
</div>
CSS
#container-5a {
align-items: normal; /* default - behaves like stretch in this case */
display: grid;
height: 400px;
}
#example-5a {}
#content-5a {
height: 80px;
}
Grid container, tall content - elements with tall content in grid containers expand to the height of the content
#container-5b
#example-5b
#content-5b
HTML
<div id="container-5b">
<div id="example-5b">
<div id="content-5b" />
</div>
</div>
CSS
#container-5b {
align-items: normal; /* default - behaves like stretch in this case */
display: grid;
height: 400px;
}
#example-5b {}
#content-5b {
height: 420px;
}
Grid container, tall content, height 100% - surprisingly, setting height to 100% does not contract an element's height to the height of its container. The element adjusts to the height of the content.
#container-5c
#example-5c
#content-5c
HTML
<div id="container-5c">
<div id="example-5c">
<div id="content-5c" />
</div>
</div>
CSS
#container-5c {
align-items: normal; /* default - behaves like stretch in this case */
display: grid;
height: 400px;
}
#example-5c {
height: 100%;
}
#content-5c {
height: 420px;
}
Grid container, tall content, overflow - elements with tall content in grid containers adjust to the height of the container if overflow is set to something other than visible
#container-5d
#example-5d
#content-5d
HTML
<div id="container-5d">
<div id="example-5d">
<div id="content-5d" />
</div>
</div>
CSS
#container-5d {
align-items: normal; /* default - behaves like stretch in this case */
display: grid;
height: 400px;
}
#example-5d {
overflow: auto;
}
#content-5d {
height: 420px;
}
Grid container, align-items - if a grid container sets
align-items to something other than
stretch (the default), then the element will adjust to the
height of the content MDN docs on align-items.
#container-5e
#example-5e
#content-5e
HTML
<div id="container-5e">
<div id="example-5e">
<div id="content-5e" />
</div>
</div>
CSS
#container-5e {
align-items: start;
display: grid;
height: 400px;
}
#example-5e {}
#content-5e {
height: 80px;
}
Grid container, align-items, tall content - elements with tall content in grid containers expand to the height of the content
#container-5f
#example-5f
#content-5f
HTML
<div id="container-5f">
<div id="example-5f">
<div id="content-5f" />
</div>
</div>
CSS
#container-5f {
align-items: start;
display: grid;
height: 400px;
}
#example-5f {}
#content-5f {
height: 420px;
}
Grid container, align-items, tall content, overflow - elements with tall content in grid containers expand to the height of the content even if overflow is set
#container-5g
#example-5g
#content-5g
HTML
<div id="container-5g">
<div id="example-5g">
<div id="content-5g" />
</div>
</div>
CSS
#container-5g {
align-items: start;
display: grid;
height: 400px;
}
#example-5g {
overflow: auto;
}
#content-5g {
height: 420px;
}
Absolute positioning¶
Absolutely positioned -
#container-6a
#example-6a
#content-6a
HTML
<div id="container-6a">
<div id="example-6a">
<div id="content-6a" />
</div>
</div>
CSS
#container-6a {
display: block; /* default */
position: relative;
height: 400px;
}
#example-6a {
position: absolute;
}
#content-6a {
height: 80px;
}
Absolutely positioned, tall content -
#container-6b
#example-6b
#content-6b
HTML
<div id="container-6b">
<div id="example-6b">
<div id="content-6b" />
</div>
</div>
CSS
#container-6b {
display: block; /* default */
position: relative;
height: 400px;
}
#example-6b {
position: absolute;
}
#content-6b {
height: 420px;
}
Absolutely positioned, height 100% -
#container-6c
#example-6c
#content-6c
HTML
<div id="container-6c">
<div id="example-6c">
<div id="content-6c" />
</div>
</div>
CSS
#container-6c {
display: block; /* default */
position: relative;
height: 400px;
}
#example-6c {
height: 100%;
position: absolute;
}
#content-6c {
height: 80px;
}
Absolutely positioned, height 100%, tall content -
#container-6d
#example-6d
#content-6d
HTML
<div id="container-6d">
<div id="example-6d">
<div id="content-6d" />
</div>
</div>
CSS
#container-6d {
display: block; /* default */
position: relative;
height: 400px;
}
#example-6d {
height: 100%;
position: absolute;
}
#content-6d {
height: 420px;
}
Floated elements¶
Floated elements - elements that set
float adjust to the
height of their content.
MDN docs on float.
#container-7a
#example-7a
#content-7a
HTML
<div id="container-7a">
<div id="example-7a">
<div id="content-7a" />
</div>
</div>
CSS
#container-7a {
display: block; /* default */
height: 400px;
}
#example-7a {
float: left;
}
#content-7a {
height: 80px;
}
Floated elements, tall content - elements that set float adjust to the height of their content
#container-7b
#example-7b
#content-7b
HTML
<div id="container-7b">
<div id="example-7b">
<div id="content-7b" />
</div>
</div>
CSS
#container-7b {
display: block; /* default */
height: 400px;
}
#example-7b {
float: left;
}
#content-7b {
height: 420px;
}
Floated elements, height 100% -
#container-7c
#example-7c
#content-7c
HTML
<div id="container-7c">
<div id="example-7c">
<div id="content-7c" />
</div>
</div>
CSS
#container-7c {
display: block; /* default */
height: 400px;
}
#example-7c {
float: left;
height: 100%;
}
#content-7c {
height: 80px;
}
Floated elements, height 100%, tall content -
#container-7d
#example-7d
#content-7d
HTML
<div id="container-7d">
<div id="example-7d">
<div id="content-7d" />
</div>
</div>
CSS
#container-7d {
display: block; /* default */
height: 400px;
}
#example-7d {
float: left;
height: 100%;
}
#content-7d {
height: 420px;
}
Table cell containers¶
Table cell container - elements in table cell containers (td and th) adjust to the height of their content by default
| Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. |
#td-container-8a
#example-8a
#content-8a
HTML
<div id="td-container-8a">
<div id="example-8a">
<div id="content-8a" />
</div>
</div>
CSS
#td-container-8a {
/* td element */
vertical-align: top;
}
#example-8a {}
#content-8a {
height: 80px;
}
Table cell container, height 100%, explicit table cell height - elements in table cell containers (td and th) expand to the height of their container if height is set to 100% and the table cell container has an explicit height set
| Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. |
#td-container-8b
#example-8b
#content-8b
HTML
<div id="td-container-8b">
<div id="example-8b">
<div id="content-8b" />
</div>
</div>
CSS
#td-container-8b {
/* td element */
vertical-align: top;
height: 400px;
}
#example-8b {
height: 100%;
}
#content-8b {
height: 80px;
}
Table cell container, height 100%, table cell height not set - surprisingly, setting
height to
100% does not expand an element's height to the height of a table cell container (
td and
th) if a height for the table cell is not explicitly set. The element adjusts to the
height of the content. Maybe the fifth bullet in the
CSSWG's "Incomplete List of Mistakes in CSS" explains this:
Percentage heights should be calculated against fill-available rather than being undefined in auto situations. | Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. |
#td-container-8c
#example-8c
#content-8c
HTML
<div id="td-container-8c">
<div id="example-8c">
<div id="content-8c" />
</div>
</div>
CSS
#td-container-8c {
/* td element */
vertical-align: top;
}
#example-8c {
height: 100%;
}
#content-8c {
height: 80px;
}